



Google’s billion parameter LLM model has a privacy first approach that could herald the age of safe AI…
These days, as Large Language Models (LLMs) continue to learn and build, they are also unintentionally memorising sensitive user data that is readily available on the internet. In the pressure for improved performance, privacy has become a major headache for AI research.
To combat that Google has announced VaultGemma, a billion-parameter model that has been trained from the ground up using rigorous differential privacy constraints. And by making public both the model weight as well as a detailed technical report, Google hopes to increase and speed up the adoption of privacy-centric AI and herald a new wave of safe and responsible AI.
How VaultGemma Pushes the Boundaries of Safe AI
Long story short, LLMs can perform a lot of time-consuming tasks very quickly. Tasks like summarisation, coding, reasoning and more. But this comes at a cost. These LLMs are trained on massive volumes of non-curated datasets. They have a tendency of memorising and repeating this information which in some cases can be private or identifiable leading to what are called ‘memorisation attacks.’
VaultGemma eliminates this risk by integrating differential privacy (DP) right from the training phase and not just during fine tuning. Differential privacy works by adding controlled ‘noise’ into the LLM’s learning process so that the model’s output does not lean heavily towards any one training sample.
But this is a trade-off. In theory, this means that no real-life example can be reverse engineered from the model. But in practice, this also means that more noise might reduce the accuracy of the results.
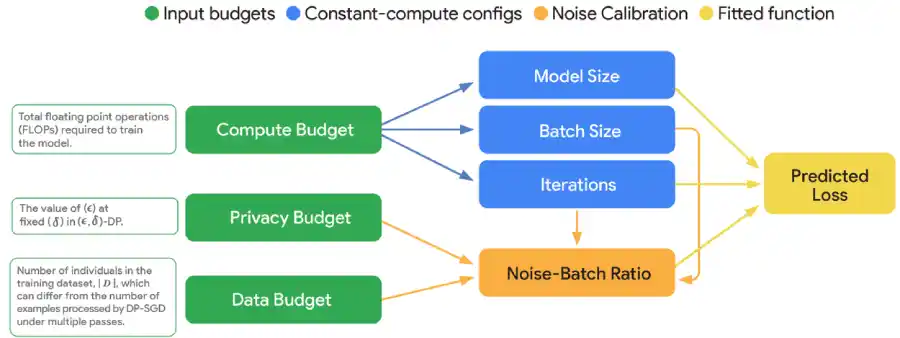
DP Scaling Laws & VaultGemma’s Design
One of the major outcomes of this project is the formulations of DP Scaling Laws. These laws guide how model performance, privacy budget, data volume and computation together affect the final outcome. The researchers assumed that the key factor affecting the outcome is the noise-to-batch ratio. They designed experiments for different model scales and noise levels to determine how privacy and utility trade-off.
Using these laws, Google built VaultGemma, a 1 billion-parameter decoder-only transformer with 26 layers and a token window of 1,024. To ensure that its privacy training is tractable, the sequence length was limited and training protocol was optimised to mitigate instability from the added noise.
How Close Is VaultGemma to “Non-Private” Models?
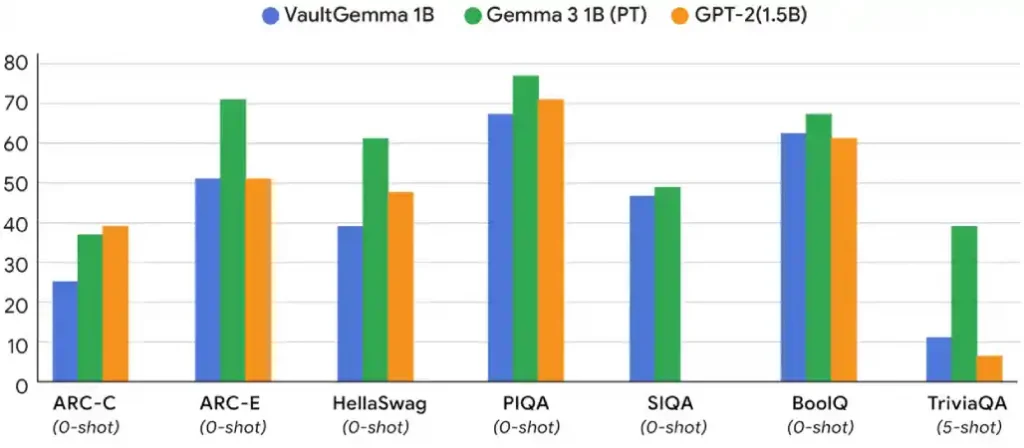
One of the major concerns about DP-trained models is that there is a massive lag in comparison with non-private counterparts. But VaultGemma has reduced that gap. In comparison the benchmarks like MMLU or BigBench, it comes very close to earlier non-private models that are of similar size.
Google’s tests have shown that VaultGemma does not memorise any of the training data compromising on performance. There is still a disparity when it comes to performance but it is comparable to models from 5 years ago.
Use Cases, Risks & Research Implications
Because VaultGemma is designed to avoid data leaks, it is well suited for industries where privacy is non-negotiable. It can be used in finance, healthcare, government and legal systems among others.
But it should also be noted that this approach is not without limitations. DP training requires bigger batch sizes, heavier computing and careful tuning. This means it is difficult for teams with low resources to use it. Also, the current version only offers example-level privacy and not user-level privacy.
Additionally, while VaultGemma is a landmark moment in the history of LLMs, it still cannot replace higher-parameter, non-private models for situations where state-of-the-art performance is needed. Google hopes that the DP scaling laws and the open release will help generate future private models with trillions of parameters.

The Last Word
VaultGemma is a statement from Google. By making the model and the methodology open source, Google has shown intent to make privacy a design goal, not a happy side-effect. This decision will result in research making inroads in various avenues, like scaling DP training to much larger models, refining user-level privacy, reducing computational overhead and combining DP with other techniques like synthetic data, secure multi-party computation or federated learning.
For AI applications in regulated sectors, VaultGemma lets them build assistants and analysis tools that can do the job without leaking data. As and when future systems combine this level of privacy with improved levels of performance, we will genuinely enter an era of safe, trustworthy AI.
In case you missed:
- Google’s HOPE Model: A Big Leap Toward AI That Never Forgets
- AI on Trial: Copyright Law caught between Innovation and Litigation
- Why Indian Startups Are Building “Vertical AI” Instead of the next ChatGPT
- Is AI marking the End of the Web Traffic Era?
- Privacy Was a Myth. AI Just Proved It
- Are Your Headphones Safe? Harmful Chemicals Found in Popular Brands
- Governments move to rein in social media and AI for children
- AI Has Already Predicted the 2026 FIFA World Cup Winner?
- Selling Yourself to AI: The Hidden Cost of Intelligence
- How the US-China Tech Rivalry is Affecting India’s Future





