



Forget big data sets and giant models; a new machine learning architecture aces logic puzzles on minuscule training and resources, threatening to change machine intelligence forever, finds Satyen K. Bordoloi
For humans, many things are easy to learn. You don’t know how to thread a needle? Someone shows you: stiffen the thread with spit, rub it between fingers, squint your eyes and gently insert the thread into the eye of the needle. Within a minute, you’ve learnt it. But try to teach the same to an AI robot. The effort and energy required to learn is humongous, if it can do it at all because there are things AI struggles given its current and near future abilities.
The solution, according to AI companies, is to feed the systems more data and provide more training.

Bigger data isn’t helping, though, as large language models (LLMs) might dazzle us with the generation of coherent prose, but when tasked to solve a hard Sudoku puzzle or navigate a labyrinthine maze, these systems falter, tripping over their Chain-of-Thought reasoning. But a recent model proposed in a paper hosted on arXiv, a preprint repository, called Hierarchical Reasoning Model (HRM) is a lean, brain-inspired marvel that doesn’t just solve these problems in AI reasoning, but promises to do so with exponentially fewer resources and training.
Sapient Intelligence, a Singapore-based AI startup, has proposed this model. As per the research paper that has yet to be peer reviewed, it can vastly outperform LLMs on complex reasoning tasks while consuming less energy and being considerably smaller than traditional LLMs.

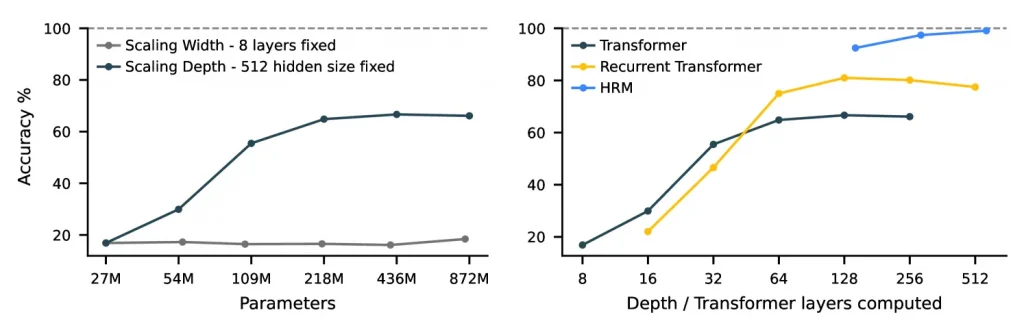
The brain inspires HRM, and how it uses different brain systems for doing various things, i.e. the brain system used for slow, deliberate planning is different from those that require fast, intuitive computation, with both operating in tandem when required. What is equally stunning is that the model learns with just 1000 examples and without any pre-training, relying on a mere 27 million parameters.
In contrast, traditional LLMs often contain billions or trillions of parameters to help them understand and generate language. With such a small dataset, HRM managed to tackle reasoning challenges that are out of bounds for the largest LLMs today.
If proven correct, the efficiency and frugality of this system could change artificial intelligence, and thus the world. After peer review and analysis, this paper could become as influential as the famous Google paper that proposed the transformer model. That paper led to LLMs as we know them, and thus the cheap and expansive proliferation of digital intelligence around the world, changing and transforming everything it touches.

From Chain-of-Thought to Latent Convergence
Traditional AI reasoning relies heavily on Chain-of-Thought (CoT) prompting, painstakingly externalising intermediate steps as tokens. This method demands vast pretraining, brittle manual decomposition, and generates a humongous token sequence that can falter when even a single step in the chain becomes misordered, leading to everything from wrong answers to hallucinations.
HRM sweeps aside this crutch by conducting its logic entirely within a latent, hierarchical recurrent architecture. Inspired by the brain’s cortical hierarchy, HRM layers two interdependent recurrent modules: a slow-updating high-level planner that crafts abstract strategies, and a fast-updating low-level executor performing intensive, detail-oriented computations.
Rather than leaking reasoning into language, HRM modules co-conspire in a single forward pass. Each high-level cycle spawns multiple low-level timesteps, during which the low-level RNN (Recurrent Neural Network) settles toward a local equilibrium. Once reached, the high-level module ingests this result, advances its state, and “resets” the low-level module to pursue a fresh equilibrium. This hierarchical convergence multiplies effective computational depth (N × T timesteps) without vanishing gradients or exorbitant memory costs.
Backpropagation Through Time (BPTT) shackles recurrent networks to O(T) memory and biologically implausible credit assignment. HRM boldly sidesteps BPTT via a one-step gradient approximation grounded in deep equilibrium theory. By backpropagating only through each module’s final state and treating preceding states as constants, the model maintains a constant O(1) memory footprint.
This lean, stable training regime lets HRM zip through learning on a single GPU in mere hours, snugly reflecting the brain’s local, short-range credit assignment.
The result, as per the paper, is new records on reasoning benchmarks when going head-to-head with CoT-based systems. When it comes to ARC-Abstraction and Reasoning Corpus – ARC-AGI-1, HRM hits 40.3 per cent accuracy, leaping past ChatGPT o3-mini-high’s 34.5 per cent and Claude 3.7 8K’s 21.2 per cent. When it came to Sudoku-Extreme and Maze-Hard benchmarks, the performance gap between HRM and the “baseline methods is significant, as the baselines almost never manage to solve the tasks,” while “a large vanilla Transformer model with 175M parameters, trained on 1 million examples across multiple trials, achieved only marginal success on 30×30 Maze tasks, with accuracy below 20% using the pass@64 evaluation metric” which the HRM manages to achieve with 55 percent correctness.
These results are stunning considering that they arise with no internet-scale pretraining, no CoT supervision, and with a mere thousand examples of training. This, if proven correct, will mean a profound shift from scale-obsessed architectures toward a more principled structural design for the same. The result: AI systems would be able to do much more, with much less training and resources.
UNDER THE HOOD
With such strong performance on complex reasoning tasks, the most natural question is: what reasoning algorithms does its neural network implement? The paper admits: “a definitive answer lies beyond our current scope,” but it does offer some answers.
In maze navigation, the low-level module initially fans out across multiple corridors simultaneously while the high-level planner prunes blocked or inefficient routes in the maze, and subsequent cycles iteratively refine the surviving path. In solving the Sudoku, “the strategy resembles a depth-first search approach, where the model appears to explore potential solutions and backtracks when it hits dead ends.” These vivid trajectories hint at the HRM’s ability to rediscover classic algorithms without explicit programming.
HRM uses a different approach for ARC tasks, making incremental adjustments to the board and iteratively improving it until it reaches a solution. What is fascinating is that “the model shows that it can adapt to different reasoning approaches, likely choosing an effective strategy for each particular task.” As the writers themselves suggest, further research to gain more comprehensive insights into these solution strategies is crucial for the growth of AI in general and LLMs in particular.

Beyond Puzzles: Real-World Implications
As you can guess, the real-world potential of this approach is enormous. The fact that it can do deep reasoning on less data means it could be used to scale up any application.
In healthcare, diagnostic AI systems could learn from limited, high-quality case studies rather than a massive, noisy corpus of medical data to adapt to new diseases or imaging modalities rapidly. In climate modelling, lean reasoning engines might extrapolate subseasonal patterns from sparse sensor arrays, offering targeted forecasts when big-data approaches falter.
For robotics, on-device planners could juggle real-time navigation and obstacle avoidance under stringent compute and memory constraints, toggling between “fast” reflexive manoeuvres and “slow” strategic planning. In enterprise, bespoke reasoning agents might be trained overnight on proprietary workflows, sidestepping the cost and risk of wholesale data sharing or enormous compute budgets.
And if this, or similar low-constraint, low-resource AI models, gain traction, it would mean a profound shift in the world order. NVIDIA became the world’s first $4 trillion company and Microsoft the second precisely because of the massively rising need for AI chips and data centres. If HRM can give the same results by using exponentially fewer resources, it would first reorient the tech world.
By making digital intelligence dirt cheap, it’ll make it that much more accessible to places like Africa in the Global South that do not usually have access to even the basic resources like the Global North. The transformative nature of such a shift is impossible to imagine at this moment.
Yet, we must stick to reality by not forgetting that HRM so far has performed only grid-based symbolic tasks like Sudoku and mazes. Its performance on open-domain natural language understanding, multimodal reasoning, or unstructured environments is still to be tested. Also, scaling hierarchical convergence to ultra-long contexts or integrating dynamic memory modules may present architectural and training complexities.
Yet HRM’s modular design means straightforward extensions can work, and vision encoders, graph-structured memory, or continuous control loops can be slotted in on the same multi-timescale reasoning core that exists today.
HRM challenges the fundamental idea of AI that gurus like Sam Altman, demanding $7 trillion to build AGI, preach: bigger is better. Along with many other approaches being researched, its success rests on effective depth – the rich, recurrent interplay of nested reasoning loops – rather than mere parameter counts. By echoing the brain’s hierarchical convergence and adaptive resource allocation, HRM achieves robust, generalizable, and computationally efficient reasoning.
Whatever be the fate of this paper and approach, it is heartening to know that newer, less resource-intensive, bio-mimicking methods are being tried out. Even if this paper fails, eventually we will have methods that achieve the holy grail of AI compute: peak performance on lean infrastructure. The future of AI isn’t brute force; it is brilliance on a budget.
In case you missed:
- Pressure Paradox: How Punishing AI Makes Better LLMs
- A Small LLM K2 Think from the UAE Challenges Global Giants
- AI Hallucinations Are a Lie; Here’s What Really Happens Inside ChatGPT
- Don’t Mind Your Language with AI: LLMs work best when mistreated?
- The Cheating Machine: How AI’s “Reward Hacking” Spirals into Sabotage and Deceit
- Bots to Robots: Google’s Quest to Give AI a Body (and Maybe a Sense of Humour)
- Building AGI Not as a Monolith, but as a Federation of Specialised Intelligences
- Google’s “Learn Your Way” is Set to Redefine Education and Challenge the AI “Dumbing Down” Narrative
- Anthropic Accuses Chinese AI of “Stealing”, Internet Points Finger Back At Them
- PhD Students, Pack Your Bags: AI Just Beat You at Your Own Game, & Without Needing Coffee





