



So far, scientists have relied on positive reinforcement learning to train LLMs, but the opposite seems to be giving much better results, finds Satyen K. Bordoloi…
This is a finding that’ll have old-school parents high-fiving AI researchers. Researchers have found that when training large language models (LLMs), negative reinforcement, i.e. punishing wrong answers, is shockingly more effective than rewarding the right ones, i.e., positive reinforcement, which has been the norm.
Forget participation trophies for everyone, this research suggests yelling “WRONG!” can help you raise better.. no, not children – LLMs. Why the parenting parallel? Because while humans resent this approach, LLMs seem to thrive on tough love. Also, the study, “The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning,” suggests we flip conventional AI training on its head, to adapt a technique straight out of old-world parenting.
The Carrot and the Binary Stick: Traditional reinforcement learning methods rely on human evaluations that are subjective or complex learned reward models. But RLVR or Reinforcement Learning with Verifiable Rewards (RLVR) has recently emerged as a method to train in those areas where correctness can be unambiguously stated, like mathematical reasoning and coding.
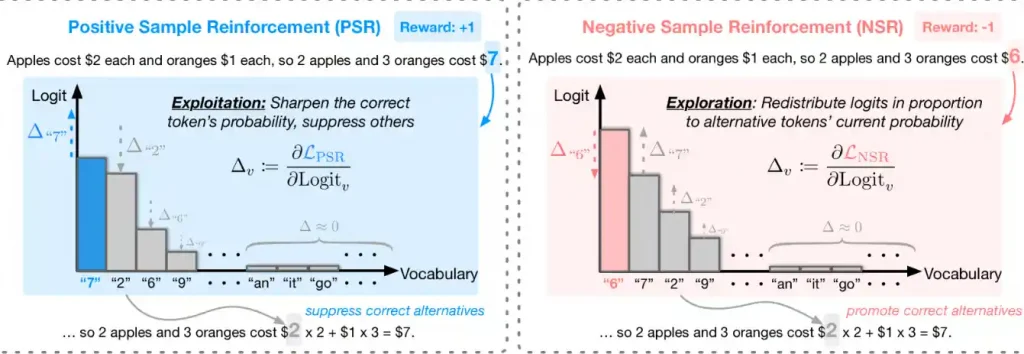
Taking this further, the researchers of this paper tested models like Qwen2.5 and Qwen3 by giving them binary rewards: +1 for correct answers, -1 for failures. This simplicity is meant to bypass the murkiness of judgments based on human preferences. The genius idea that the researchers came up with is to dissect RLVR into two psychological modes: Positive Sample Reinforcement (PSR), which is like an overenthusiastic coach who cheers correct answers, and Negative Sample Reinforcement (NSR), which behaves like a strict professor who circles errors in red ink.
This NSR doesn’t just punish: with surgical precision, it suppresses wrong tokens and redistributes probability to other options based on the model’s existing knowledge. It is like a teacher saying, “Try again, but maybe take a different approach this time.” She’s not just scolding, but also suggesting you change how you do it.
When Wrong Answers Shape Genius: Researchers designed a rigorous experiment to pit PSR against NSR. They trained Qwen2.5-Math-7B and Qwen3-4B on 7,500 problems from a mathematical dataset. For each problem, the models generated eight reasoning paths (“rollouts”). They changed the test by updating some models only when they failed (NSR), while the others only when they succeeded (PSR).
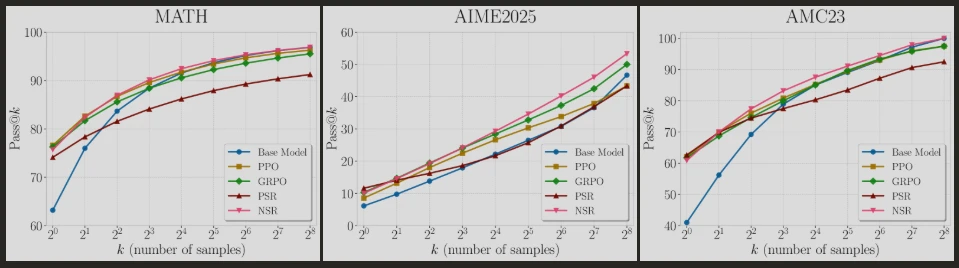
Overall performance was measured using Pass@k – the probability that at least one of “k” generated answers hits the mark. Why this metric? In the real world, reasoning isn’t about getting the answer on the first try but exploring before the conclusion. Generating 256 solutions to crack a tricky problem mirrors how our mind brainstorms, except with AI, it happens at the speed of light. Crucially, both NSR and PSR used fewer samples than the industry standard reinforcement learning algorithms i.e. PPO – Proximal Policy Optimization or GRPO – Group Relative Policy Optimization, proving their efficiency. So, who won – PSR or NSR?
Why “Wrong” Works Wonders: The results astounded the researchers because they were counterintuitive. NSR, i.e., training solely on failures, outperformed every other training method. Models ‘punished’ for wrong answers improved their Pass@k scores even at k=256, often matching or surpassing sophisticated algorithms like PPO and GRPO. Astonishingly, NSR boosted Pass@1 without seeing a single correct example, akin to acing a test after studying only your mistakes without ever knowing the correct answer. Perhaps to explain this, I’ll paraphrase Sherlock: whatever remains after negating all the wrong answers must be the correct answer.

That was not the only finding of this research, because their PSR (reward-only training) revealed a fatal flaw. While it showed improved immediate accuracy (Pass@1), its performance faltered at higher ‘k’ values. Why? It seems that PSR models are one-trick ponies that obsessively recycle reinforced paths. Output diversity collapsed as variety increased. This is akin to a student memorising one formula for every problem. For Qwen3-4B’s “non-thinking” mode, PSR couldn’t unlock inherent skills for the model, while NSR acted like a drill sergeant extracting peak performance.
They discovered the secret after doing a gradient analysis. When penalising wrong tokens, the NSR method boosts the system’s ability to find alternatives in proportion to their existing likelihood or in the words of the researchers, it “discourages wrong responses and redistributes probability mass according to the model’s prior knowledge, improving the full Pass@k spectrum.” Think of it like a chef who made a mistake. Instead of abandoning the whole dish, NSR helps the cook figure out alternate approaches, such as reducing salt.
NSR also self-regulates, i.e., it only updates or changes its approach if errors persist. Once the correct answer or approach is found, it stops chasing new approaches, thus locking in on the successful one and preventing overkill. This is perhaps what is needed for LLMs; as models hit scaling limits, such techniques that enhance reasoning, instead of chasing size, will become essential.

The Goldilocks Algorithm: So, should we abandon PSR completely and go for NSR itself? The answer, sorry for bringing the parenting parable again, lies in how we raise our children. Parents who use too much negativity (NSR) on their children end up giving them trauma that lasts a lifetime. The opposite isn’t productive either, i.e. when parents who do not scold their kids at all (the modern approach) and are always positive (PSR), either raise fragile snowflakes or maladjusted adults who struggle all their lives. The right way, then, as the Buddha said, is the middle path. Indeed, that is what the researchers also found with LLMs.
While PSR improves Pass@1, i.e. when the variables are fewer, it deteriorates when in Pass@k, with the ‘k’ being large. The opposite is true for NSR, i.e. they’re great when the ‘k’ value is large but may underperform when the ‘k’ value is small. Hence, the researchers propose the middle path – “a simple weighted combination of PSR and NSR”, “allowing the model to learn from both correct and incorrect samples.” They call this proposed Weighted-REINFORCE (W-REINFORCE) – a balanced objective that quietens PSR’s overzealousness while amplifying NSR at the same time. The results are promising as such models outperformed PPO and GRPO by preserving diversity and accuracy.
So, what does NSR teach us about effective machine learning? A lot. First and foremost, it rejects the entire Western idea of more the merrier for LLMs. i.e., you do not necessarily need more data to train a model better, which the likes of Sam Altman have been preaching while asking for over a trillion dollars to create AGI. You do not need to inject new behaviours into the models, especially when the base model is strong. All you need to do is refine existing knowledge and change the training parameters to improve model performance. W-REINFORCE offers a simple, open-source alternative to complex reinforcement learning pipelines.
This is not without challenges. NSR falters in extended training without PSR to temper things down. Secondly, it works best when the final results are objective and verifiable like mathematics or code, not necessarily for subjective tasks like say writing. And a lot of work still needs to be done to understand NSR’s effect on weaker models, or its practicality in say LLM training.
Despite these, this is a new idea, and it opens a door for humanity. We must walk into it to figure out better ways of machine learning so we can create better AI. And who knows what else? The fate of AI and human progress depends on it.
In case you missed:
- The Cheating Machine: How AI’s “Reward Hacking” Spirals into Sabotage and Deceit
- 100x faster AI reasoning with fewer parameters: New model threatens to change AI forever
- A Small LLM K2 Think from the UAE Challenges Global Giants
- Don’t Mind Your Language with AI: LLMs work best when mistreated?
- The Digital Yes-Man: When AI Enabler Becomes Your Enemy
- Building AGI Not as a Monolith, but as a Federation of Specialised Intelligences
- Reviving Old Research With AI: How It Can Transform The World
- The AI Prophecies: How Page, Musk, Bezos, Pichai, Huang Predicted 2025 – But Didn’t See It Like AI Is Today
- Can AI Solve Quantum Physics?
- PhD Students, Pack Your Bags: AI Just Beat You at Your Own Game, & Without Needing Coffee





